Evolving a Recurrent Spiking Neural Network on a Partially Observable Variant of CartPole
Abstract
This project explores the use of recurrent spiking neural networks (RSNNs) to solve a partially observable version of the classic CartPole control problem. The agent's observations are limited to only the cart's position and the pole's angle, with both the cart velocity and the pole’s angular velocity omitted. As a result, the agent must implicitly infer these hidden variables within its recurrent neurons. The internal parameters of each neuron, as well as the topology and weights of a leaky integrate-and-fire RSNN are evolved using a genome based evolutionary algorithm. The performance is compared to several baseline policies, including random action selection and the naive policy for the partially observable state. Results show that the evolved RSNN reliably balances the pole by implicitly estimating the missing velocities, outperforming all baselines policies.
Evolved RSNN (Generation 272) (avg: 1002.50)
CartPole
CartPole is a classic benchmark in reinforcement learning and control theory. The environment consists of a cart that can move left or right along a track, with a pole hinged to its top. The goal is to keep the pole balanced upright by applying forces to the cart to move it left or right. The cart itself must also stay on the screen. In the standard version, the agent receives four observations at each timestep: the cart's position, cart velocity, pole angle, and pole angular velocity.
In this project, the environment is made more challenging by restricting the agent's observations to only the cart's position and the pole's angle. All velocity information is hidden, making the problem partially observable. This means the agent must infer the missing velocities from the sequence of past observations, rather than having direct access to them. This restricted version is far closer to how humans approach this problem - the only things we can see are the position of the cart and pole, and we infer the velocities within our brains based on our memory of the previous frames.
Simple Policy Baselines
Simple, non-neural network policies:
- Go Left / Go Right: Always pushes the cart in the same direction (left or right) at every timestep, regardless of the pole's state.
- Random: At each timestep, randomly chooses to push the cart left or right, with no regard for the environment state.
- Naive: At each timestep, applies force to the cart in the direction that would reduce the pole's angle (e.g., if the pole is leaning left, push left). Without memory, this is the best approach available using the given information. However, without any implicit calculation of velocity, this policy is purely reactive and eventually loses control of the pole.
Go Left (avg: 9.36)
Go Right (avg: 9.36)
Random (avg: 22.25)
Naive (avg: 42.12)
Recurrent Spiking Neural Networks
Recurrent Spiking Neural Networks (RSNNs) are a class of artificial neural networks that combine two key features: recurrence and spiking dynamics.
- Recurrent: The network contains connections that loop back, allowing information to persist over time. This enables the network to maintain an internal memory of past inputs, which is crucial for tasks where the current observation is insufficient to determine the optimal action—such as in partially observable environments like this version of CartPole. These internal “loops” of activating neurons are one of the mechanisms put forward to explain how short term memory functions in humans, though our understanding of all the mechanisms involved is still murky.
- Spiking: Unlike traditional neural networks that use continuous activations, spiking neurons communicate via discrete events ("spikes") that occur when a neuron's activation level crosses a threshold. In this project, each neuron follows a leaky integrate-and-fire model: it integrates incoming spikes which increase voltage, the voltage decays over time in the absence of incoming spikes, and when the voltage exceeds a threshold it itself emits a spike and its internal voltage resets.
The combination of recurrence and spiking enables RSNNs to process sequences of inputs and to infer hidden variables—such as the unobserved velocities in CartPole—by integrating information over time. However, the non-differentiable nature of spiking makes these networks challenging to train with standard gradient-based methods.

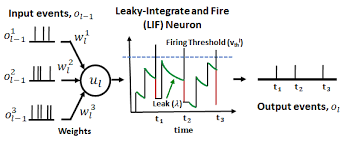
Genetic Evolution
To train the RSNN for the CartPole task, a genetic (evolutionary) algorithm is used. Evolutionary algorithms are well-suited for this problem because the spiking dynamics are non-differentiable, making gradient-based learning infeasible.
Each individual agent in the population encodes a complete RSNN "genome," which specifies:
- Network topology: Which neurons are connected to which, including recurrent connections.
- Synaptic weights: The strength of each connection between neurons, and whether it's positive or negative.
- Neuron parameters: Properties such as voltage threshold for spiking and the rate at which voltage decays (leakiness).
This approach allows the discovery of both the architecture and the detailed dynamics of the spiking network, starting from pure randomness and without any hand-designed solutions.
Results
The evolved RSNN consistently achieves stable control of the CartPole system using only partial observations, far surpassing the performance of all baseline policies. The RSNN effectively reconstructs the missing state variables over time through recurrent neural loops, forming a crude short term memory. Future work includes training the RSNN on more complex environments, and eventually attempting to build a mechanism for long term memory through allowing synapse modification over the course of a single agent-life.